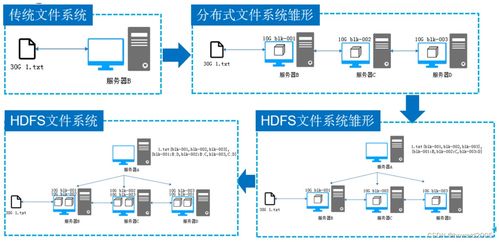
Hadoop分布式文件系統(HDFS)是Apache Hadoop生態系統的核心組件之一,專為處理大規模數據集而設計。它提供了一個高度可靠、可擴展且容錯的存儲解決方案,是支撐現代大數據處理與分析的基礎設施。
一、HDFS的基本架構
HDFS遵循主從(Master-Slave)架構,主要由兩個核心組件構成:
- NameNode(主節點):作為HDFS的“大腦”,負責管理文件系統的元數據(如文件名、目錄結構、文件塊位置等)。它維護著整個文件系統的命名空間,并協調客戶端對文件的訪問。
- DataNode(從節點):負責實際的數據存儲。文件被分割成固定大小的數據塊(默認為128MB),并分布式地存儲在多個DataNode上。DataNode定期向NameNode報告其存儲狀態,確保數據的完整性和可用性。
HDFS還包含Secondary NameNode(輔助節點),它并非NameNode的實時備份,而是定期合并編輯日志與文件系統鏡像,協助NameNode減輕元數據管理的負擔。
二、HDFS的關鍵特性
- 高容錯性:數據默認被復制為三個副本,存儲在不同機架的DataNode上。即使某個節點或機架發生故障,數據仍可從其他副本恢復。
- 高吞吐量訪問:HDFS優化了順序讀寫操作,適合批處理任務(如MapReduce),而非低延遲的隨機訪問。
- 可擴展性:通過橫向添加DataNode,HDFS可輕松擴展到數千個節點,支持PB級數據存儲。
- 經濟性:基于商用硬件構建,降低了存儲成本。
三、HDFS在數據處理與存儲中的角色
作為數據處理和存儲的支持服務,HDFS在以下場景中發揮關鍵作用:
- 數據湖基礎:企業常將HDFS作為數據湖的核心存儲層,集中存儲結構化、半結構化和非結構化數據,為后續的ETL、分析和機器學習提供統一數據源。
- 批處理支持:HDFS的高吞吐量與Hadoop MapReduce、Spark等批處理框架無縫集成,支持對海量數據進行離線分析。
- 數據冗余與備份:通過副本機制,HDFS確保了數據的持久性和可靠性,減少了因硬件故障導致的數據丟失風險。
- 流式數據處理:結合Kafka、Flume等工具,HDFS可作為流式數據的最終存儲目的地,支持實時或近實時分析。
四、HDFS的局限性
盡管HDFS功能強大,但也存在一些限制:
- 不適合存儲大量小文件,因為NameNode的元數據存儲受內存限制。
- 不支持文件的隨機修改,僅允許追加寫入。
- 高可用性需通過NameNode的HA配置實現,增加了部署復雜度。
五、未來演進
隨著云原生和對象存儲(如AWS S3)的興起,HDFS的部署模式也在變化。許多企業開始采用混合存儲策略,將HDFS與云存儲結合,以平衡性能、成本與彈性。HDFS自身也在持續優化,例如通過糾刪碼(Erasure Coding)替代副本機制以提升存儲效率。
HDFS作為大數據時代的基石,通過分布式、容錯的存儲設計,為數據處理提供了堅實后盾。理解其基本概念與特性,有助于更有效地構建和維護大規模數據平臺。